Deep Motifs and Motion Signatures
Deep Motifs and Motion Signatures
Andreas Aristidou, Daniel Cohen-Or, Jessica K. Hodgins, Yiorgos Chrysanthou, Ariel Shamir
ACM Transaction on Graphics, 37(6), Article 187, 2018.
Proceedings of SIGGRAPH Asia 2018.
We introduce deep motion signatures, which are time-scale and temporal-order invariant, offering a succinct and descriptive representation of motion sequences. We divide motion sequences to short-term movements, and then characterize them based on the distribution of those movements. Motion signatures allow segmenting, retrieving, and synthesizing contextually similar motions.
[DOI] [paper] [bibtex] [Supplementary Materials]
The dance motion capture data used can be downloaded from the Dance Motion Capture Database website.
Abstract
Many analysis tasks for human motion rely on high-level similarity between sequences of motions, that are not an exact matches in joint angles, timing, or ordering of actions. Even the same movements performed by the same person can vary in duration and speed. Similar motions are characterized by similar sets of movements that appear frequently. In this paper we introduce motion motifs and motion signatures that are a succinct but descriptive representation of motion sequences. We first break the motion sequences to short-term movements called motion words, and then cluster the words in a high-dimensional feature space to find motifs. Hence, motifs are words that are both common and descriptive, and their distribution represents the motion sequence. To cluster words and find motifs, the challenge is to define an effective feature space, where the distances among motion words are semantically meaningful, and where variations in speed and duration are handled. To this end, we use a deep neural network to embed the motion words into feature space using a triplet loss function. To define a signature, we choose a finite set of motion-motifs, creating a bag-of-motifs representation for the sequence. Motion signatures are agnostic to movement order, speed or duration variations, and can distinguish fine-grained differences between motions of the same class. We illustrate examples of characterizing motion sequences by motifs, and for the use of motion signatures in a number of applications.
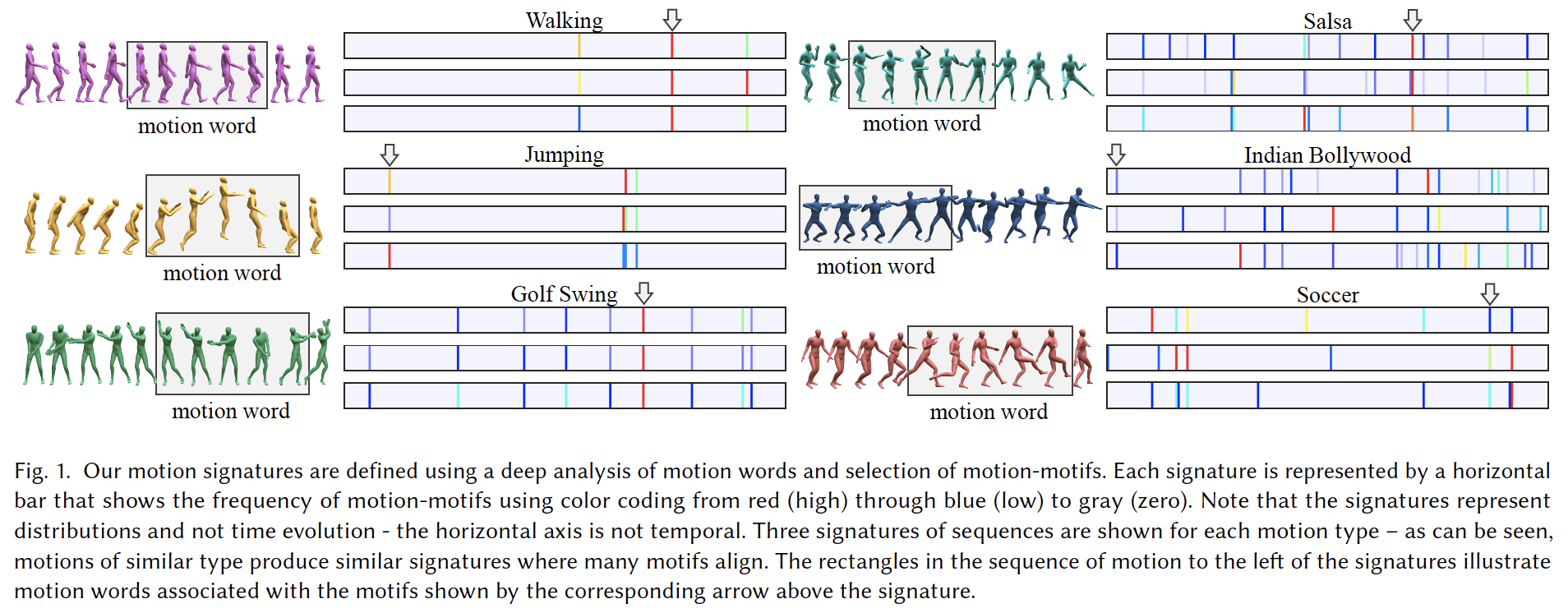
The main contributions of this work include:
- Defining a high-dimensional universal feature space for motion words, where Euclidean distances reflects semantic similarity among local movements represented by words,
- Defining motion-motifs as common and discriminative motion-features in animation,
- Defining motion signatures: succinct and descriptive high-level representations of motion sequences, that reflect the distribution of motion-motifs found in the sequences.
Acknowlegments
This research was supported by the Israel Science Foundation as part of the ISF-NSFC joint program grant number 2216/15; the work was also partially supported by ISF grant 2366/16, and the European Union's Horizon 2020 research and innovation programme H2020-WIDESPREAD-01-2016-2017-Teaming Phase 2 under grant agreement No 739578. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research.



© 2025 Andreas Aristidou