Latent Space Skinning: Learning Compact Representations for Mesh Animations

Overview
Latent-Space Skinning (LSS) is a neural character animation framework that replaces explicit skinning weights with a shared latent representation of skeletal motion and rest-pose geometry, which is decoded into per-vertex mesh deformations over time. This compact and expressive latent space enables high compression ratios, accurate reconstruction, and intuitive motion manipulation operations such as blending and cross-character transfer.
Abstract
We present Latent-Space Skinning (LSS), a neural formulation of character animation that recasts the classical skinning pipeline as a learned mapping from skeletal motion and rest-pose geometry to mesh deformation. Instead of explicitly computing skinning weights, LSS jointly encodes skeletal motion and rest-pose geometry into a shared latent space and decodes this representation into per-vertex deformations over time. This formulation remains compatible with standard animation workflows while capturing complex non-linear deformations within a single unified model, reducing reliance on handcrafted rigging components. The learned latent representation is both compact and expressive, enabling high compression ratios while preserving reconstruction quality. Operating in latent space further allows for intuitive manipulation of motion through interpolation and conditioning. We demonstrate applications such as motion blending and cross-character transfer as proof-of-concept examples, illustrating the flexibility of the proposed representation. Our results show strong reconstruction performance at high compression rates, highlighting the potential of latent representations as a foundation for motion manipulation within modern animation pipelines and as a compelling data-driven alternative to traditional skinning.
Architecture
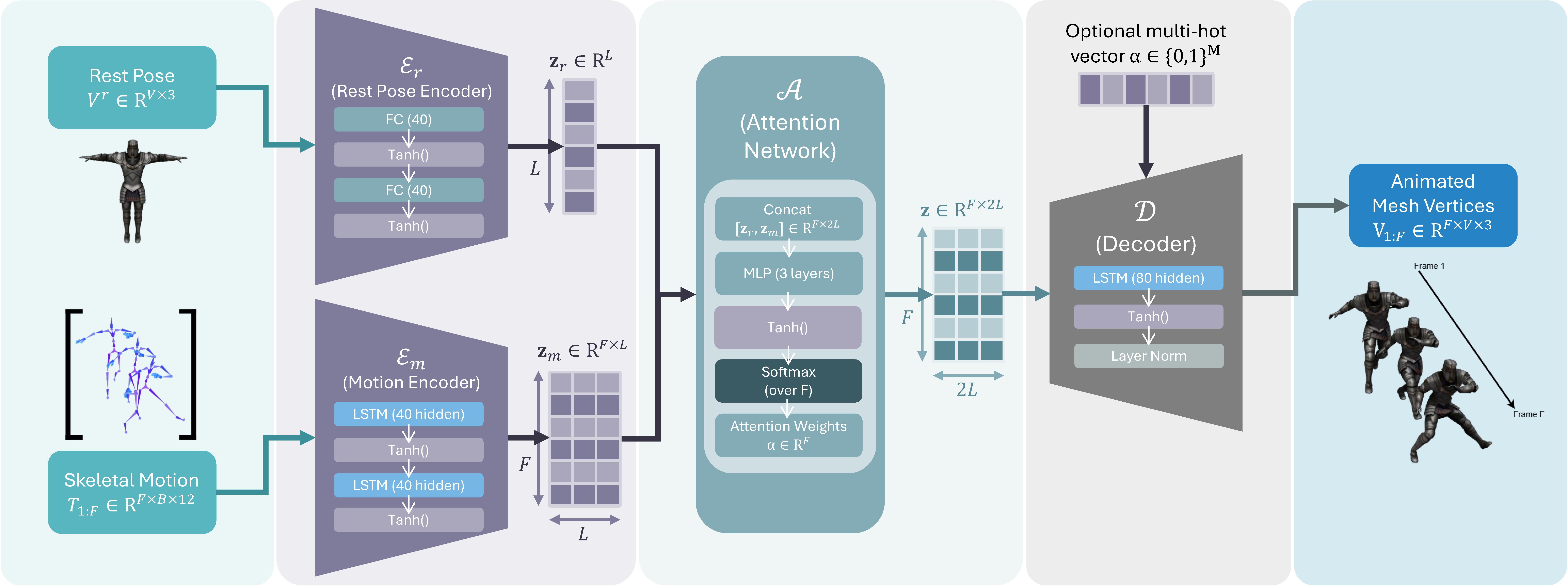
Figure 1: LSS architecture. The motion sequence T1:F and rest mesh Vr are encoded into latent representations zm and zr. These are fused via 𝒜 to produce z, which is decoded by 𝒟 into vertex trajectories V1:F. Here, the latent dimension is L = 40, F is the number of frames, B is the number of bones, and V is the number of vertices.
Video
Contributions
- Latent-space formulation of skinning. We reinterpret the classical skinning pipeline as a learned mapping from skeletal motion and rest-pose geometry to mesh deformations, avoiding explicit skinning weights while preserving compatibility with existing animation pipelines.
- Compact motion-conditioned representation. We introduce a latent-space representation that jointly encodes temporal skeletal motion and shape-dependent deformation for reconstructing mesh animations, enabling significant compression of animation data while maintaining reconstruction quality.
- Latent-space operations as proof-of-concept applications. We demonstrate that the learned representation supports operations such as motion blending and animation transfer, illustrating its flexibility. These applications are presented as proof-ofconcept, indicating the potential of the latent formulation while motivating future work on cross-character and cross-topology alignment.
BibTeX
Not available yet